
A few years ago, it was fashionable to argue that all IoT data must end up in the cloud and that all the really smart stuff was therefore in the cloud. This was a throwback to machine-to-machine (M2M), when we expected data from all connected devices to be sent to a central server for processing and subsequent distribution of the information created.

CEO
Beecham Research
That approach was the most cost-effective method, given the types of applications that were being connected at the time, which were not time critical for business operations. Typically, they were kinds of status monitoring of activities that could require some field support like repair, replenishment, reset, and so on. Since then, the opportunities for connecting assets and devices have evolved considerably. Several billion devices are now connected to the Internet using an increasing variety of connectivity technologies – fixed line, Bluetooth, cellular, LoRa, Sigfox, Wi-Fi and satellite to name a few. All incur costs in one form or another. Over the next few years, many more billions are expected to be connected. As they multiply, many will need near-real time processing of the data they generate, as IoT becomes more central to business operations. Further, IoT in the enterprise is rapidly encompassing business-critical activities where any interruption of service could be catastrophic.
What is edge processing and what are the key benefits?
Edge processing refers to the execution of data aggregation, manipulation, bandwidth reduction and other logic directly on an IoT sensor or device. In the context of enterprise IoT, which includes industrial IoT (IIoT), ‘edge’ refers to the computing resource close to the sources of data, for example industrial machines such as wind turbines, industrial controllers supervisory control and data acquisition (SCADA ) systems and magnetic resonance (MR) scanners. These edge computing devices typically reside away from the centralised computing available in the cloud.
The aim is to put basic computation as close as possible to the physical system, making the IoT device itself as ‘smart’ as possible. Only the data that needs to go to the cloud is sent there. This could be to put data from an individual device into a wider context, such as data analytics related to the performance of a complete solution.
Processing data at the edge has several key benefits, in particular:
- Bandwidth and storage costs – as the amount of data required for ‘smart’ operations increases, and the number of Internet-connected devices continues to grow, the cost of sending data to the cloud and storing it centrally also grows. The bandwidth cost can be significantly reduced by only sending data to the cloud that is required for operations at that level and sending it in summarised form. Local processing at or near the edge reduces the amount of bandwidth needed.
- Reliability – a primary motivation for edge adoption is robust and reliable support for hard to reach environments. Many industrial and maintenance businesses cannot rely on internet connectivity for mission-critical applications. As noted in the example above, connected cars cannot meet their potential without local processing. Even wearables need to be resilient to work effectively without constant connectivity. For these use cases and many more, being reliable offline makes all the difference.
- Latency – is the time difference between an action and a response. The latency introduced by sending data to the cloud, processing it centrally, the return journey to the edge and then the data being acted on incurs delays that may be unacceptable when near-real-time actions are required. Manufacturing companies cannot afford this delay for their mission-critical systems. For example, cutting power to a machine just too late is the difference between avoiding and incurring physical damage.
- Privacy and security – a system that relies on connectivity to the cloud inherently presents more security risks. Data privacy is related to this: protecting privacy is both a potential asset and a risk for businesses in a world where data breaches occur regularly. Companies largely reliant on cloud technology have been scrutinised for what they know about users and what they do with that information.
Centralised cloud
Centralised data centres are farthest from the network edge. However, they offer a much greater density of compute, storage, and networking resources.
Edge infrastucture
Small, distributed data centres provide a resource-dense midpoint between edge devices and the centralised cloud. Low roundtrip latencies of 5-10ms.
Edge devices
Real-time data processing within devices is based on applications’ needs.
Edge sensors & chips
Data collection & origination
How should edge processing be organised?
As Internet-connected devices proliferate, the efficiency of data transmission and processing is becoming increasingly important. Cloud computing has traditionally provided a reliable and costeffective method for handling data, but the continuing, rapid growth in IoT has created a need for lower network latency and higher reliability. Edge processing is emerging to meet these demands.
It involves placing computing resources closer to where the data originates – such as motors, pumps, generators – or at the ‘edge’ where there are sensors. These processing resources may be located in the devices themselves or in edge infrastructure at a slightly higher level that can act as small, local data centres.
For example, Tesla cars have powerful onboard computers which allow data processing in near-real time, collected by the vehicle’s many peripheral sensors. This enables the vehicle to make timely, autonomous driving decisions.
On the other hand, in the healthcare sector, most wireless medical devices do not have the resources to process and store large streams of complex data. As a result, smaller, modular ‘data centres’ are deployed to provide storage and processing capacity at the edge.
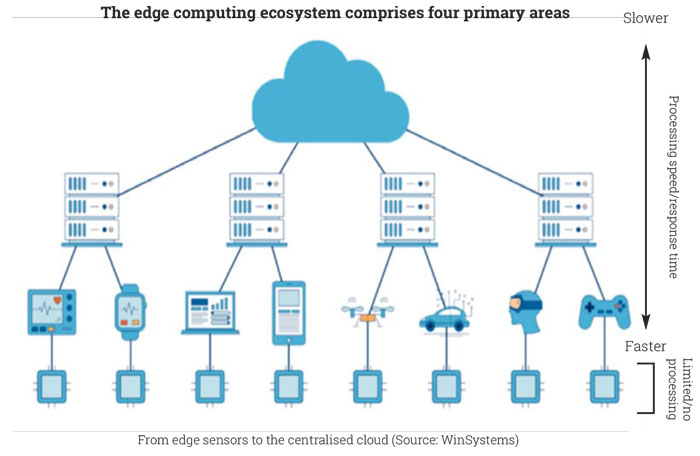
The chart illustrates four layers for the evolving edge processing ecosystem:
- Edge sensors and chips are where data is collected initially. They include sensors and chips manufactured for a wide range of use cases in addition to the standard application-specific integrated circuits (ASICs) and application-specific standard products (ASSPs), which are optimised for specific use cases.
- Edge devices provide the first line of processing and storing of sensor information. They include the edge sensors and chips, which collect the data, as well as the computational resources to process and analyse it, to an extent. These edge devices range from smart watches to autonomous vehicles.
- Edge infrastructure – data centres come in all shapes and sizes. More recently, microdata centres are being deployed to offer a very local, resource-intensive midpoint between the edge devices and the centralised cloud. They provide far more data processing and storage capacity than the edge devices themselves, and extremely low latency compared with the centralised cloud, which could be located a long way away.
- Centralised cloud has become a a primary location for storing, analysing and processing large-scale data sets, but is not the place for analysing data and delivering insights in real time. It is where data from many different sources at the edge is aggregated to provide an overall system perspective or other historic data. It is also where most of the integration between operational technology (OT) data and IT data tends to happen, for ongoing distribution to the wider enterprise.
The edge infrastructure level can aggregate data from edge devices or edge sensors, or both. One example is the recentlylaunched mPower Edge Intelligence offered by MultiTech. It extends the functionality of MultiTech router and gateway products. mPower Edge Intelligence simplifies integration with a variety of popular upstream IoT platforms to streamline edge-to-cloud and management and analytics, while also providing the programmability and processing capability to execute critical tasks at the edge of the network.
This reduces latency, controls network and cloud service costs, and ensures core functionality – even in instances when network connectivity may not be available. It also provides strong security features.
Integrating OT and IT
The OT domain involves operational processes like industrial and factory automation, supply chain management and asset monitoring: the IT domain involves business process and office automation, enterprise web and mobile applications where data is consumed. Integrating OT and IT brings together the whole enterprise into one system, sharing the same data.
The OT can benefit from this integration with a more efficient, scalable, managed and secure infrastructure into which numerous applications are layered. They include predictive maintenance and remote asset monitoring and management.
Benefits on the IT side include secure real-time communication with the enterprise’s assets while retaining the requisite efficiency for creating, scaling, maintaining and securing the infrastructure. The result is an opportunity for better operational performance, protection of profit margins, customer retention and the creation of new business models.
In this way, edge processing for IoT is not just an opportunity to improve operational performance. It has implications throughout the enterprise that ultimately impact both its efficient use of resources and potential for cost reduction, as well as the ability to compete in the market through superior customer support.
Extreme examples
Take as one extreme example the future of connected, autonomous vehicles. If they relied exclusively on a wireless network to operate, as mobile handsets do, what would happen if a network suffered downtime? What would happen if those vehicles needed to operate in areas where there was poor or no coverage? Even in areas with good coverage, if all the data processing for vehicle operations were conducted in the cloud, it would take time to send the data for central processing and then return it to the vehicle to be acted on. That latency could be more than 100ms for each vehicle, which is an eternity when considering the traffic issues, even in a medium-sized city. In addition, this method would demand an enormous amount of processing in the cloud for all the vehicles that may be connected at any one time. It would also consume large amounts of cellular connectivity and the costs associated with it.
A question of balance
As this shows, some connected devices need their data processing to be carried out in real time with minimal latency and with no risk of downtime. That means close to the point where the data is created – at the network’s edge where the devices are located. In the case of autonomous vehicles, processing data at the edge is critical to the operation of the vehicle itself, but other data, such as warnings of incidents well ahead and potential traffic delays, and even booking service appointments can still be processed centrally. This means there is a balance to be struck for each type of application – how much processing should be carried out at the edge versus in the cloud? At the same time, connectivity to the cloud comes at a cost – in particular, when using cellular or even satellite connectivity. Enterprise IoT users must assess all of this when defining requirements for their IoT solution.
Privacy in healthcare
Privacy is an acute issue in healthcare. For instance, in the US under the Health Insurance Portability and Accountability Act (HIPPA). Each hospital bed currently has about 20 sensors and it is estimated (by IBM) that data breaches cost the healthcare industry three times more than any other sector. As the number of sensors collecting and processing data continues to grow, privacy represents real value for healthcare companies looking to balance innovation with protection of patients’ data. Edge processing helps to alleviate some of these concerns by bringing processing and collection into the environment where the data is produced. If necessary, it can then be encrypted.